

量化交易实战策略:用KMeans聚类寻找支撑位(附miniqmt开通攻略)
发布时间:2026-3-4 17:03阅读:320
 问一问
问一问今天我们来分享一下用聚类(KMeans)来找到价格的密集区,从而判断股票的支撑与压力位。
废话少说,开门见山。
开始前的准备:
我这里用的行情数据源是 xtquant + miniQMT。 后续示例里会用到一些常见的 Python 库:pandas, numpy, matplotlib,进阶部分还会涉及 scipy, sklearn。在实际运行代码之前,记得先把环境配置好:

这样就能避免因为依赖缺失导致的报错啦。以下是一个基于xtquant + miniQMT获取股票行情的方法,后面的行情Dataframe数据都会通过这个方法来获取:
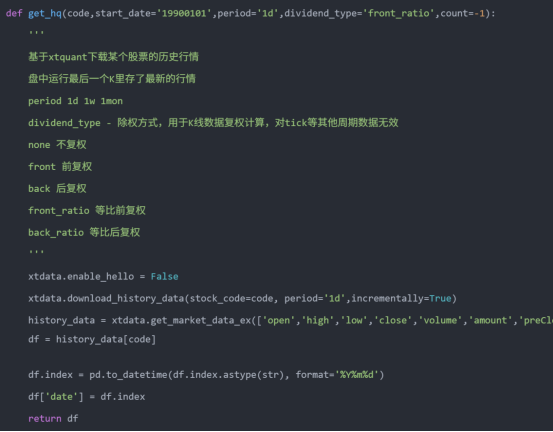
一、 KMeans是什么?
KMeans 是一种无监督学习算法(Unsupervised Learning)。
“无监督”意思是:我们没有事先标注数据的类别,算法要自己去发现规律。
它的任务就是:把一堆数据自动分成 K 个簇(Clusters),每个簇有一个“中心点”(Center)。
换句话说,KMeans的工作就是帮我们回答:“这堆数据里,有哪些是比较接近的,可以分到一类里去?”
在股票里,我们把“价格”作为数据点,KMeans就能帮我们找到几个最密集的价格水平。
举个例子,
想象股价就像一部电梯,在不同楼层上下运行。
过去半年,电梯停过很多楼层(这些楼层就是每天的收盘价)。
有的楼层只停过一次,有的楼层停了好多次,电梯门一开一关,人来人往特别多。
这时候你作为大楼管理员,就想知道:“这部电梯最常停在哪些楼层?”
KMeans怎么做?
1. 随机选楼层:一开始,KMeans随便挑几个楼层,假设它们是“重点停靠楼层”。
2. 分配楼层:把每次电梯停靠的记录(股价)分配到离它最近的重点楼层。
3. 更新楼层位置:重新计算这些重点楼层的平均位置(比如把 149、151、152、150 都分到一组,那么这一组的“平均楼层”大概是 150.5)。
4. 反复迭代:电梯的停靠数据一遍遍调整,直到那些重点楼层稳定下来。
最后,KMeans就会告诉你:电梯最常停的 5~7 个楼层在哪儿。
对应到股票,
电梯楼层 = 股价水平
电梯停靠次数 = 股价在某个价位的出现频率
重点停靠楼层 = 聚类中心(价格密集区)
这些“重点楼层”就是市场最记忆深刻的位置:
电梯上行时,到了这里可能遇到人多拥堵 → 压力位
电梯下行时,到了这里容易有人支撑 → 支撑位
数学定义KMeans的目标函数是最小化平方误差和(SSE):
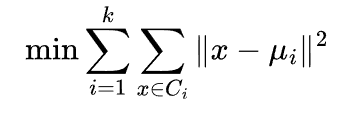 其中:
其中:
k:要分的簇数(自己设定,比如 5 个)。
C_i:第 i 个簇的数据集合。
u_i:第 i 个簇的中心。
简单说就是:找一组中心点,使得每个数据点距离它的中心点尽可能近。
在股票的量化交易里,KMeans最常见的应用有:
(1)股票聚类: 把几百只股票的因子特征(市盈率、波动率、换手率等)输入进去,算法会自动把相似的股票分到一类。这样我们能发现哪些股票“同病相怜”,或者属于同一风格。
(2)板块特征分析: 把行业里的个股做聚类,看看哪些公司走势接近,能帮助我们识别板块效应。
(3)因子分层: 对某个因子值(比如动量因子)进行聚类,得到“高动量、中动量、低动量”三组,为后续策略分层打下基础。
(4)价格行为研究: 把历史价格点输入KMeans,找到最常出现的价格水平 → 这就是我们要重点讲的:价格密集区。
总结
关注"叩富问财"公众号,回复"资深吴经理",联系专属客户经理开通量化交易权限!
立即行动:打开微信,搜索"叩富问财",在对话框中输入"资深吴经理",开启你的量化交易之旅!
温馨提示:投资有风险,选择需谨慎。

 +微信
+微信
 当前我在线
最快30秒解答
当前我在线
最快30秒解答

文章很精彩?转发给需要的朋友吧 
 分享该文章
分享该文章
 如何通过历史价格数据寻找股票的重要支撑位?
股票支撑位是怎么形成的?为什么会有支撑位?
如何通过历史价格数据寻找股票的重要支撑位?
股票支撑位是怎么形成的?为什么会有支撑位?









-
GDP半年报出炉!如何解读?下半年怎么看?
 2026-07-20 11:43
2026-07-20 11:43
-
你还在交万5的佣金?一年可能多花6000块(附省钱攻略)
2026-07-20 11:43
-
客户经理执业编号怎么查?中证协官网3步验证教程(2026最新版)
2026-07-20 11:43


