

LDA模型:量化交易中热点挖掘的核心工具
发布时间:2025-10-14 17:13阅读:486

 问一问
问一问在量化交易中,“热点轮动”是长期有效的策略逻辑之一。然而,市场热点往往隐藏在海量的新闻资讯、研报评论等非结构化文本中,如何高效、准确地挖掘这些热点并转化为交易信号,成为策略落地的关键难题。今天讲解的LDA(Latent Dirichlet Allocation,潜在狄利克雷分配)模型作为自然语言处理领域的经典主题建模工具,为这一问题提供了成熟的解决方案。本文将从LDA模型的基本原理出发,详细解析其在量化热点选股中的应用方法,并梳理实际操作中的核心注意事项,为量化交易者提供系统性参考。
一、什么是LDA模型:
LDA模型由David Blei、Andrew Ng和Michael Jordan于2003年在NeurIPS会议上提出,是一种基于贝叶斯概率框架的无监督主题建模算法。其核心目标是从大量无标签文本中,自动挖掘出潜在的“主题”,并建立“文本-主题-词汇”的三层概率映射关系。
1.1 LDA的核心思想:概率生成模型的逆向推理
LDA的本质是模拟人在“写作过程”的概率生成模型,再通过逆向推理还原文本背后的主题结构。它假设一篇文本的生成遵循三个步骤:首先,从狄利克雷分布(由参数α控制)中抽样得到该文本的“主题分布”,例如一篇财经新闻可能包含60%“新能源”、30%“半导体”、10%“消费”的主题权重;其次,针对文本中的每个词,从上述主题分布中随机选择一个主题;最后,从该主题对应的词汇分布(由参数β控制)中抽样得到具体词汇,例如“新能源”主题可能以高概率抽到“储能”“光伏”“政策支持”等词。
在量化交易场景中,我们已知的是海量的热点资讯文本,LDA的作用就是通过吉布斯采样或变分推断等算法,逆向求解出两个核心输出:一是θ(文本-主题分布),即每篇资讯属于各个热点主题的概率;二是φ(主题-词汇分布),即每个热点主题包含的核心词汇及其概率。通过这两个输出,我们就能将零散的文本转化为结构化的热点信息。
1.2 LDA的技术优势:为何适用于量化热点挖掘
相较于其他文本分析技术,LDA在量化热点挖掘中具备三大优势:一是无监督学习特性,无需人工标注热点主题,可自动适应市场热点的动态变化,避免了人工标注的滞后性和主观性;二是概率解释性强,θ和φ均以概率形式输出,便于量化策略设定明确的阈值(如“热点主题占比超过50%则触发信号”);三是可扩展性好,既能处理新闻、研报等长文本,也能适配股吧评论、政策摘要等短文本,且可与其他量化指标(如资金流向、量价数据)无缝融合。
二、LDA模型在量化热点选股中的实操步骤
将LDA模型应用于量化热点选股,需经过“数据准备-模型训练-热点匹配-个股筛选”四个核心环节,每个环节都需结合量化交易的时效性和准确性要求进行针对性设计。
2.1 数据准备:构建高质量的金融文本语料库
数据质量直接决定LDA模型的热点挖掘效果。量化交易场景下的文本数据需满足“全、新、准”三大标准:“全”即覆盖多源文本,包括权威财经新闻(如财新网、东方财富网)、券商研报(Wind、同花顺)、政策文件(国务院、发改委官网)及市场舆情(股吧、微博财经);“新”即保证实时性,需通过API接口或爬虫工具获取T+0级别的文本数据,避免因信息滞后错过热点窗口;“准”即经过严格的预处理,具体包括:
· 去噪与规范化:去除文本中的HTML标签、广告链接、特殊符号,统一中英文大小写,将“新能源车”“新能源汽车”等同义表述归一化;
· 专业分词:加载金融领域自定义词典(如“北向资金”“光刻胶”“储能装机量”),使用HanLP等工具进行分词,避免专业术语被错误拆分;
· 停用词过滤:剔除“的”“了”“因为”等无信息价值的通用停用词,以及“关注”“据悉”等金融文本中的高频无意义词。
2.2 模型训练:参数优化与热点主题提取
LDA模型的训练需重点关注参数设置和热点筛选两个环节,实际应用中无需从零构建算法,可通过成熟Python函数库实现,核心常用库包括gensim(封装简洁、功能完善,适合快速落地)、scikit-learn(API风格统一,便于与其他机器学习模型联动)、lda(轻量级专用库,专注吉布斯采样实现),通过pip install 库名即可完成安装。核心参数包括:主题数K(需挖掘的热点数量)、α(文本主题多样性)、β(主题词汇多样性)。其中,K的选择需系统结合量化评估与人工解读——A股市场通常不会同时存在超过5个核心热点,可先通过“困惑度”和“连贯性得分”量化评估(困惑度越低、连贯性越高,主题语义合理性越强),再结合人工解读验证主题的实际意义。例如,当K=3时,若困惑度从K=2时的120降至105,连贯性从0.4升至0.6,且三个主题的核心词汇分别对应“储能”“半导体国产替代”“消费复苏”等逻辑清晰的方向,则K=3更适合当前语料;若出现主题词汇交叉混乱(如“储能+白酒”),即使量化指标达标,也需调整K值或重新清洗数据。
训练完成后,需筛选出“有效热点主题”:一方面计算主题热度(如过去24小时内属于该主题的文本数量占比),保留热度Top3的核心热点;另一方面强化主题命名与有效性的人工干预——LDA模型仅输出核心词汇组合,需人工结合市场逻辑为主题命名(如将“储能、装机量、政策支持”组合命名为“储能政策驱动”主题),同时判断主题是否具备实际交易价值(如避免将“宏观经济数据”这类泛化主题纳入选股范围)。若出现“储能+白酒”等矛盾词汇组合,则需重新调整参数或清洗数据。此外,模型动态性处理是实战关键:市场热点具有时效性,需采用“滑动窗口”或“在线学习”机制更新模型——滑动窗口可设定固定周期(如每日用过去7天的文本数据重新训练模型),平衡时效性与稳定性;在线学习则通过增量训练(仅用新文本更新已有模型参数,无需全量重训)实现实时响应,适合高频交易场景,但需注意控制增量数据的噪声累积。
2.3 热点匹配:从主题到个股的精准映射
将LDA挖掘的热点主题与个股关联,需避免简单的行业分类匹配(如将“储能”直接映射为电力设备行业所有个股),推荐采用“业务文本相似度匹配法”:首先,收集全市场个股的主营业务描述、年报业务摘要等文本数据;其次,将热点主题的核心词汇(如“储能”主题的“储能系统”“电池储能”)与个股业务文本进行余弦相似度计算;最后,筛选相似度≥0.3的个股,形成该热点的初始个股池。这种方法能精准捕捉个股与热点的业务关联,例如将“储能”主题与专注于储能电池的企业匹配,排除电力设备行业中仅做传统变压器的个股。
2.4 个股筛选:量化指标融合与风险控制
初始个股池可能包含数十只股票,需通过多维度量化指标筛选出“热点内的优质标的”。推荐结合三类指标:基本面指标(净利润增速≥15%、ROE≥8%、资产负债率<60%)、技术面指标(近5日成交量放大30%以上、股价站稳20日均线)、资金面指标(北向资金近3日净流入、主力资金连续2日加仓)。同时,需加入风险控制模块:单一个股仓位不超过组合的5%,当热点主题热度低于20%时强制平仓,避免热点退潮导致的大幅回撤。
三、LDA模型应用的核心注意事项
尽管LDA模型在热点挖掘中效果显著,但在量化交易实操中仍需规避三大常见误区,确保策略的稳定性和可靠性。
3.1 避免“文本噪声”干扰:重视数据预处理的细节
量化交易对热点的准确性要求极高,文本中的噪声可能导致LDA挖掘出虚假热点。例如,若未过滤掉“某券商推荐关注储能板块,但需警惕估值过高风险”中的负面表述,可能导致模型误将“储能”主题的热度高估;若未归一化“宁德时代”“宁德”“宁时代”等公司简称,可能导致个股匹配时出现遗漏。因此,需建立“预处理-验证-迭代”的闭环:预处理后随机抽取10%的文本检查分词和归一化效果,若错误率超过5%,则需优化自定义词典或停用词表。
3.2 警惕“模型过拟合”:强化回测与样本外验证
LDA模型的参数(如K、α、β)若仅通过某一段历史数据优化,可能导致策略在新市场环境下失效。例如,在2020年新能源牛市中优化的K=2(仅挖掘“新能源”“消费”两个热点),在2023年AI热点崛起时会无法捕捉新主题。因此,需进行严格的回测和样本外验证:将2018-2022年的数据作为训练集优化参数,2023年数据作为样本外测试集,若样本外年化收益较训练集下降超过30%,则需重新调整参数或增加文本数据源。
3.3 拒绝“单一依赖”:LDA需与多因子模型融合
LDA模型仅能捕捉“热点主题”这一维度的信息,若单独依赖其输出进行交易,可能忽略市场情绪、宏观经济等其他关键因素。其中,“热点因子”需明确数学定义,常用方式包括:一是“主题热度因子”,即个股所属热点主题的文本数量占比(如个股A属于“储能”主题,该主题过去24小时文本占比为30%,则因子值为0.3);二是“个股-主题关联度因子”,即个股业务文本与热点主题核心词汇的余弦相似度(如个股A与“储能”主题的相似度为0.6,则因子值为0.6);三是“主题情感因子”,结合情感分析给热点主题赋予情感分值(如正面新闻占比60%则因子值为0.6)。例如,当LDA挖掘出“半导体”为核心热点,但宏观经济数据显示PMI大幅下滑(经济收缩信号)时,单纯买入半导体个股可能面临系统性风险。因此,需将上述“热点因子”与传统量价因子(如动量因子、波动率因子)、宏观因子(如PMI、社融数据)融合,构建多因子模型,通过因子权重动态调整(如热点因子在市场情绪高涨时权重提高至40%,在情绪低迷时降至20%),提升策略的抗风险能力。
四、结语
LDA模型为量化交易中的热点挖掘提供了科学的方法论,其“无监督主题建模”特性完美适配市场热点的动态变化。然而,LDA模型并非“万能工具”,其效果取决于数据质量、参数优化和策略融合的细节设计。对于量化交易者而言,需将LDA视为“热点探测器”,而非“交易决策机”——在充分理解其原理和局限的基础上,结合量化交易的风险控制逻辑,才能真正发挥其在热点轮动策略中的核心价值,实现从“文本信息”到“交易收益”的有效转化。
附录:模拟策略代码及输出示例
以下为LDA热点选股的简化模拟代码片段(纯模拟数据,仅逻辑参考),含核心流程与输出结果,供快速理解实操逻辑:
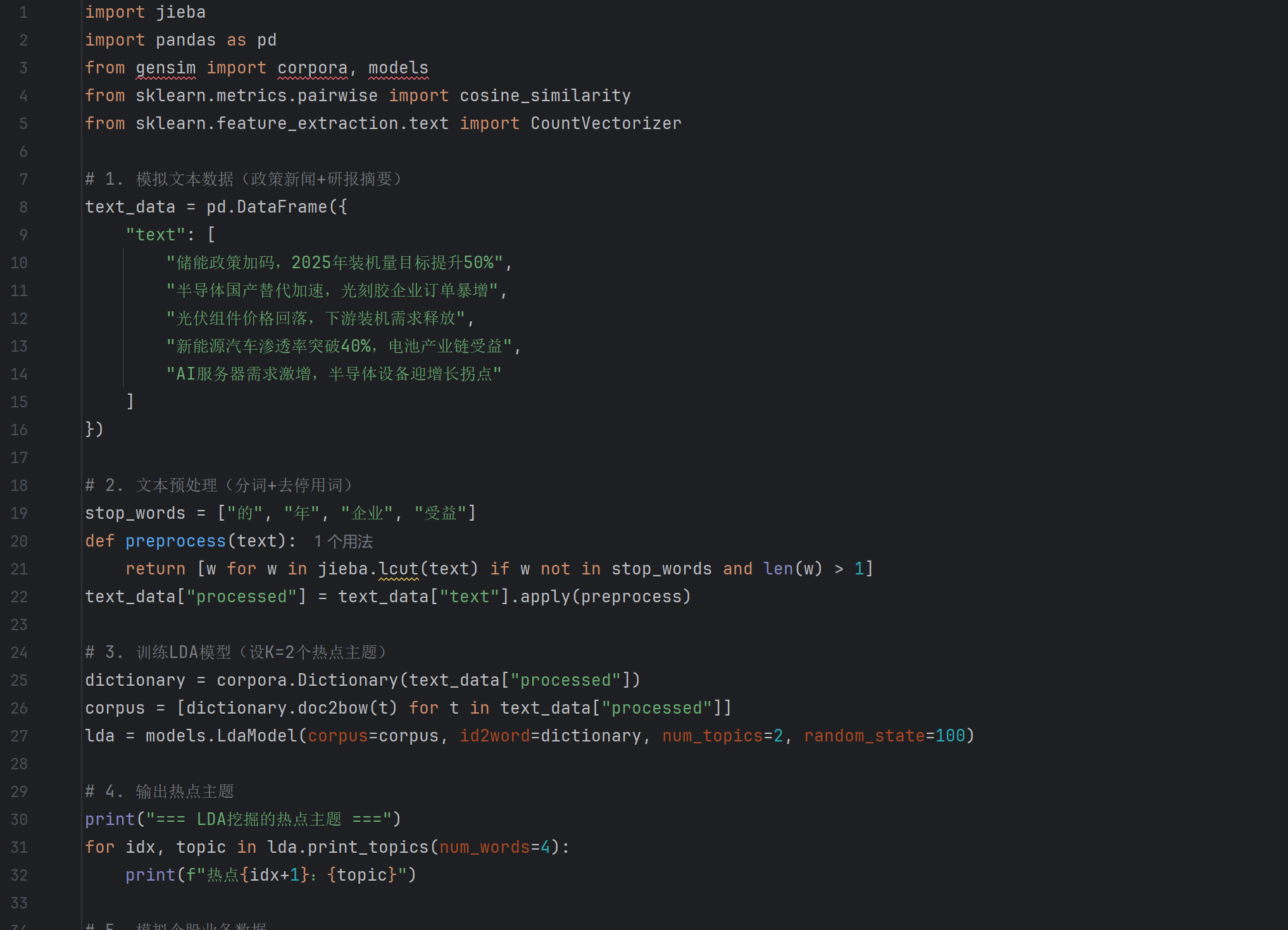 输出结果示例:
输出结果示例: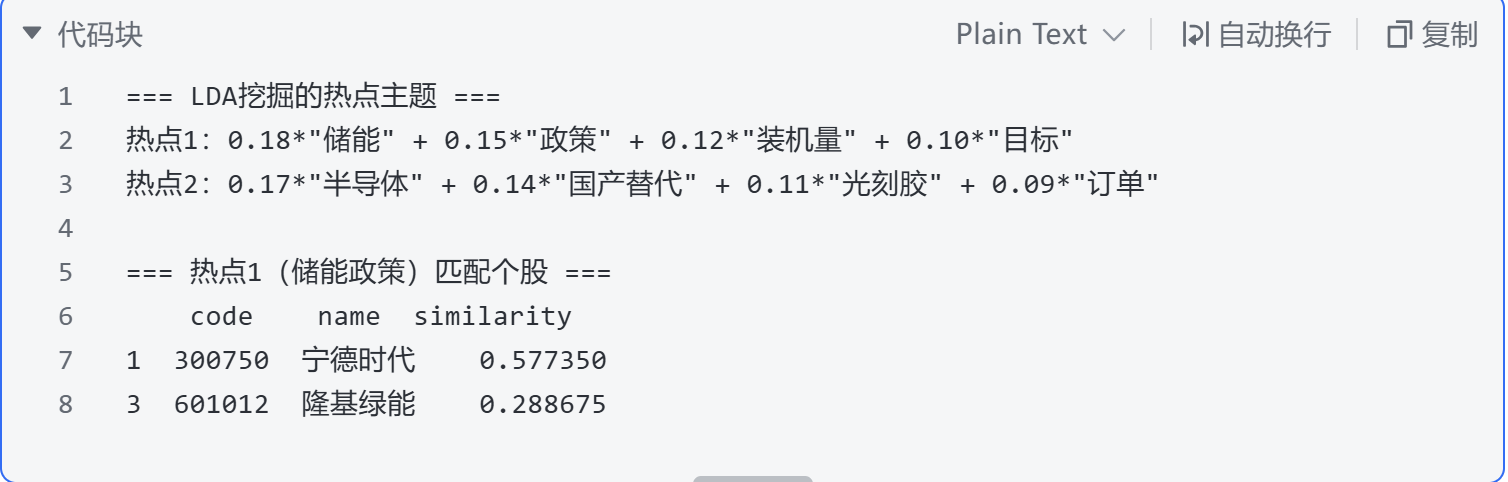
如需测试账户或策略模板,立即联系我获取专属支持!
温馨提示:投资有风险,选择需谨慎。


 +微信
+微信
 当前我在线
最快30秒解答
当前我在线
最快30秒解答

文章很精彩?转发给需要的朋友吧 
 分享该文章
分享该文章














-
GDP半年报出炉!如何解读?下半年怎么看?
 2026-07-20 11:43
2026-07-20 11:43
-
你还在交万5的佣金?一年可能多花6000块(附省钱攻略)
2026-07-20 11:43
-
客户经理执业编号怎么查?中证协官网3步验证教程(2026最新版)
2026-07-20 11:43


